|
Рубрика:
Безопасность /
Угрозы
|
Facebook
Мой мир
Вконтакте
Одноклассники
Google+
|
 ВИЗИТКА ВИЗИТКА
Владислав Рябышкин,
руководитель группы сопровождения технологических проектов «Лаборатории Касперского»
Что, если мы были взломаны?
Мониторинг угроз с помощью исторического анализа (ретросканирования) в TI-платформах
Что делать, если защитное решение для рабочей станции, например, Kaspersky Endpoint Security, обнаружило вредоносное программное обеспечение? Обращаем ли мы внимание на эти инциденты? Когда и как к нам попал зловред, что он успел сделать до обнаружения и как предотвратить повторение атак такого типа?
Истина всегда выходит на свет,
в итоге она всегда выясняется.
Стивен Кинг, «Сияние»
Домашним пользователям на практике достаточно хорошей антивирусной защиты, которая включает, конечно, и надёжную поведенческую защиту от шифровальщиков. Рассмотрим данную тему в контексте организаций, экономических субъектов, которые управляют информационными рисками – идентифицируют их, анализируют, создают механизмы оценки и снижения ущерба, осуществляют непрерывный мониторинг и устраняют факторы рисков высокой значимости.
В управленческом смысле это означает, что организации задумываются о том, не взломаны ли они, ищут признаки возможного взлома и, найдя, предпринимают усилия по устранению последствий и предотвращению заражения такого типа в будущем.
В таких организациях, как правило, существует подразделение Security Operations Center (SOC), центр управления безопасностью – в виде либо внутреннего подразделения службы ИБ, либо предоставляемого партнёром сервиса. Специалисты SOC постоянно наблюдают за событиями в защищаемой среде, выявляют инциденты и реагируют на них. Для эффективного управления информационными рисками важно, чтобы у подразделения SOC были выстроены и регламентированы рабочие процессы со специалистами и менеджерами всех уровней организации. Нельзя переоценить важность поддержки со стороны в первую очередь руководства высшего звена.
SOC – это в первую очередь специалисты, работающие по процессам и использующие соответствующие технические решения. При обнаружении инцидента важно не терять время, раздумывая, что же делать. Требуется план действий для реагирования, а это и есть основа процесса. Хорошо, когда инструменты подталкивают к действиям и показывают картину происходящего, позволяя, в частности, выявить все возможные риски.
Предположим, на одном из защищаемых узлов сети появилась неизвестная ранее угроза. Вредоносное программное обеспечение (ВПО) ещё не обнаруживается используемым средством антивирусной защиты с актуальными на данный момент антивирусными базами, так как не попало в поле зрения вирусных аналитиков. Вредоносный системный процесс иногда обращается за обновлениями и командами на сервер злоумышленников. Сетевой адрес этого сервера до сих пор оставался незаметным и не был включён в списки известных индикаторов компрометации, обновления которых регулярно получают инструменты SOC для обнаружения подозрительных сетевых активностей.
В SOC используются два типа индикаторов: IoC (Indicator of Compromise, или индикатор компрометации) и IoA (Indicator of Attack, или индикатор атаки).
IOC (indicator of compromise) – перечень данных об угрозах (например, строки, описывающие путь к файлам или ключи реестра), который даёт возможность, используя автоматизированный анализ программными средствами, выявить наличие угрозы в инфраструктуре (более подробно термин раскрывается в статье Показатели компрометации как средство снижения рисков).
Файлы со сведениями об IoC могут соответствовать открытым стандартам описания индикаторов компрометации, например OpenIOC или STIX. При выявлении индикаторов из подобных файлов в событиях, которые поступают в SOC в рамках процесса мониторинга, SOC регистрирует событие обнаружения потенциальной угрозы ИБ. Вероятность обнаружения может повыситься, если в результате проверки были найдены совпадения данных об объекте с несколькими IoC-файлами или если информация об угрозе поступила от доверенного источника с высокой репутацией.
Индикатор IoA – это правило, содержащее описание подозрительного поведения в системе, которое может являться признаком целевой атаки. Другими словами, это последовательность действий: например, успешное фишинговое письмо может приходить от якобы известного жертве адресата и побуждать нажать на ссылку или открыть заражённый файл. После компрометации вредоносное ПО незаметно запускает другой процесс, прячась в памяти и не сохраняясь на диск, чтобы избежать обнаружения как можно дольше. На следующем шаге происходит обращение к центру управления для получения дополнительных функциональных модулей или дальнейших инструкций. Идентификаторы атаки описывают эти шаги и цели атакующего. При применении IoA нет предварительного знания о самом вредоносном ПО (т.е. индикаторов IoC), а обнаружение происходит на основе корреляции цепочки событий, в результате которой могут быть получены новые IoC.
Сопутствующим эффектом применения IoA-правил является возможность собирать и анализировать, что происходит в сети. SOC проверяет все события безопасности от различных источников – антивирусных систем, журналов операционных систем, сканеров анализа защищённости, сетевого оборудования, выискивая в потоке известные индикаторы атаки. Для работы SOC нужны инструменты, позволяющие ежесекундно просеивать десятки тысяч событий.
Какие события потенциально имеют отношение к инцидентам ИБ?
Правильный ответ – «практически все». Чтобы удостовериться, что он не выдуман, достаточно обратиться к базе MiTRE ATT&CK. Корпорация MiTRE сформировала и развивает базы техник и атак, которые могут быть описаны, не опираясь на сигнатуры уже известных угроз. Некоторые производители ИБ-решений ориентируют свои продукты на базу знаний ATT&CK. Для определения атомарных типов событий, которые есть смысл собирать для анализа, архитектор SOC может опираться на описания в матрице MiTRE. Если событие не может использоваться в составе техники или тактики MiTRE, его можно игнорировать.
Традиционный инструмент SOC – это система класса SIEM, позволяющая собирать, хранить и коррелировать между собой большое число событий. Базы индикаторов компрометации c хорошим покрытием, так называемые фиды Threat Intelligence (TI), насчитывают миллионы записей. Для эффективной работы с ними используются специализированные инструменты, работающие в интеграции с SIEM.
В таком сценарии исходные события, например, могут пересылаться из SIEM на TI-платформу. Платформа в режиме реального времени выполняет выявление известных индикаторов компрометации, формируя так называемые «детекты», обогащённые информацией об угрозе. Обогащённые детекты сами по себе являются событиями и могут направляться обратно в SIEM для последующего использования в корреляционных правилах.
Кроме того, TI-платформа позволяет решать ряд вспомогательных задач: подключать новые потоки данных (фиды) от разных поставщиков, анализировать их пересечения и вклад в детектирование, а также ложноположительные срабатывания, искать индикаторы по собранной базе, исследовать инциденты графическим способом и выявлять пропущенные угрозы с помощью функции исторического анализа (ретроскана).
На TI-платформу следует пересылать не все события, а лишь те, что содержат индикаторы. Обычно это интернет-адреса (URL, IP-адрес) и контрольные суммы файлов. Например, события о неуспешных попытках входа пользователя в ОС хотя и важны для расследования инцидентов в принципе, но сопоставлять их с индикаторами компрометации из Интернет, будет лишь генерировать избыточную нагрузку.
Вот так может выглядеть исходное событие от одного из популярных источников, которое нужно анализировать TI-платформе:
<169>date=2022-03-27 time=14:43:16 logver=52 devname=043-SH-FW02 devid=QPSTP4G2DB5PVH4A
logid=0147054612 type=utm subtype=webfilter eventtype=ftgd_allow level=notice vd=root
policyid=1 sessionid=3123295974 user="CHRIS.FALZON" srcip=192.168.1.24 srcport=58853
srcintf="port2" dstip=66.171.121.44 dstport=80 dstintf="port1" proto=6 service=HTTP
hostname="www.fakess123bn2.nu" profile="Webfilter-Profile-all" action=passthrough
reqtype=referral url="/du?externalID=FD36317&cookie_version=2
×tamp=1747962599&ext_data=" sentbyte=304 rcvdbyte=60135 utmaction="allow" direction=outgoing
msg="URL belongs to an allowed category in policy" method=domain cat=140 catdesc="custom1"
Поначалу пугающе, не правда ли? Что в этом наборе символов не мусор, что вообще нужно из подобного события извлекать? Что анализировать в реальном времени, а что есть смысл дополнительно сохранять для ретроспективного анализа?
Выделим шрифтом наиболее информативные части:
<169>date=2022-03-27 time=14:43:16 logver=52 devname=043-SH-FW02 devid=QPSTP4G2DB5PVH4A
logid=0147054612 type=utm subtype=webfilter eventtype=ftgd_allow level=notice
vd=root policyid=1 sessionid=3123295974 user="CHRIS.FALZON" srcip=192.168.1.24
srcport=58853 srcintf="port2" dstip=66.171.121.44 dstport=80 dstintf="port1" proto=6
service=HTTP hostname="www.fakess123bn2.nu" profile="Webfilter-Profile-all" action=passthrough
reqtype=referral url="/du?externalID=FD36317&cookie_version=2 ×tamp=1747962599&ext_
data=" sentbyte=304 rcvdbyte=60135 utmaction="allow" direction=outgoing
msg="URL belongs to an allowed category in policy" method=domain cat=140 catdesc="custom1"
Видим, что в некоторый момент времени (date=2022-03-27 time=14:43:16) процесс пользователя (user="CHRIS.FALZON") на компьютере в локальной сети (srcip=192.168.1.24) обратился к сайту (hostname="www.fakess123bn2.nu" … url="/du?externalID=FD36317&cookie_version=2×tamp=1747962599&ext_data="). Это обращение прошло успешно (utmaction="allow"), то есть политика на шлюзе/файрволле не препятствовала посещению адреса[1].
Аналитик SOC наверняка захочет видеть такие атрибуты события, как дата, пользователь, хост, вне зависимости от того, в реальном времени произошёл детект или же обнаружен впоследствии функцией ретроскана. TI-платформа должна показывать «за деревьями лес» и гибко выделять из длинного события нужный для расследования контекст. Обратим внимание, что адрес страницы, к которой происходило обращение, в исходном событии лога разбит на две части – hostname и url. Для корректного детектирования эти части нужно воссоединить.
Если обнаружение индикатора компрометации произошло в реальном времени, TI-платформа может обогатить событие полным контекстом, возвращая в SIEM любые поля исходного события, включая и порт-источник, и названия профилей, и идентификатор сессии на шлюзе.
Детекты обычно составляют малую долю от числа событий в трафике, поэтому обогащение не повлияет существенным образом ни на аппаратные ресурсы, ни на зависящее от числа событий лицензирование SIEM. В этом можно убедиться путём просмотра дашборда со статистикой детектирования.
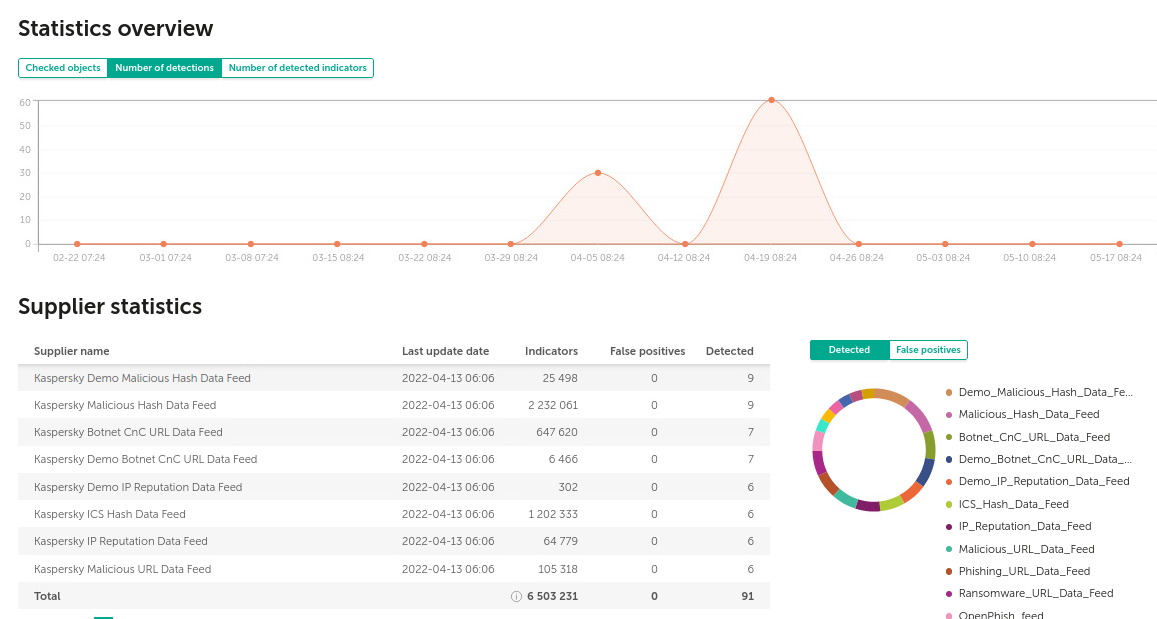
Но если детекта не произошло, есть смысл сохранить событие в TI-платформе для пересканирования, на случай появления в будущем маски, покрывающей адрес www.fakess123bn2.nu/du?externalID=FD36317&cookie_version=2×tamp=1747962599&ext_data=
Почему детекта может не быть сразу?
С помощью базы данных индикаторов компрометации возможно установить поведение лишь известных вредоносных программ. В статье о многоуровневом подходе к кибербезопасности перечислены несколько технологий обнаружения угроз, начиная от сигнатур и заканчивая методами выявления неизвестных образцов ВПО.
Новизна и полиморфность (когда код немного меняется каждый раз, как в случае троянца Emotet) угрозы – не единственная возможная причина пропуска инцидента в режиме реального времени.
В идеально настроенной системе технологии всех уровней защиты включены и обмениваются информацией, но на практике возможны ошибки конфигурации и применения политик, неправильное понимание возможностей и внедрение неверных средств защиты.
Например, организация может не обрабатывать журналы DNS-сервисов, полагаясь на обязательность использования прокси-сервера, логи которого обрабатываются. Возникает риск присутствия на компьютерах процесса-троянца, периодически пытающегося обратиться по DNS-имени к командному центру ботнета и не проявляющего вредоносного поведения в случае невозможности разрешить имя. Если бы логи DNS анализировались с помощью TI, вероятность обнаружения троянца была бы выше.
Процесс выйдет из «спящего состояния», если командный центр станет доступным. Сетевое событие обращения к командному серверу может быть лишь однократным, после чего ВПО «мутирует», получает новые адреса командных центров. Такое событие останется незамеченным в случае неверной приоритизации инцидента специалистами первой линии SOC или если произойдёт в обход корпоративного прокси-сервера в условиях удалённой работы.
Подобные факторы приводят к пропуску угроз в реальном времени и повышают важность ретроспективного сканирования, которому и посвящена данная статья.
Что именно из исходного события разумно сохранять для последующего использования? Нужен баланс между необходимостью экономить на ресурсах системы хранения данных и желанием сохранить всю полноту информации на долгое время. Обычно период хранения для ретроскана настраивают на период от двух недель до трёх месяцев, но и в случае недель размер хранилища может вырасти до терабайт. Промышленные платформы позволяют настраивать размеры сохраняемых логов и полей событий.
Вернёмся к рассматриваемому примеру атаки. Допустим, из-за (пока ещё) неизвестности адреса сервера мы, возможно, не обнаружим инцидент в момент обращения, но эффективная TI-платформа запомнит необходимые детали о сетевом событии обращения к ресурсу, выделит из него кандидатов на индикаторы компрометации. В зависимости от источника событий это может быть IP, URL или хеш-сумма для файла (SHA256, MD5, SHA1).
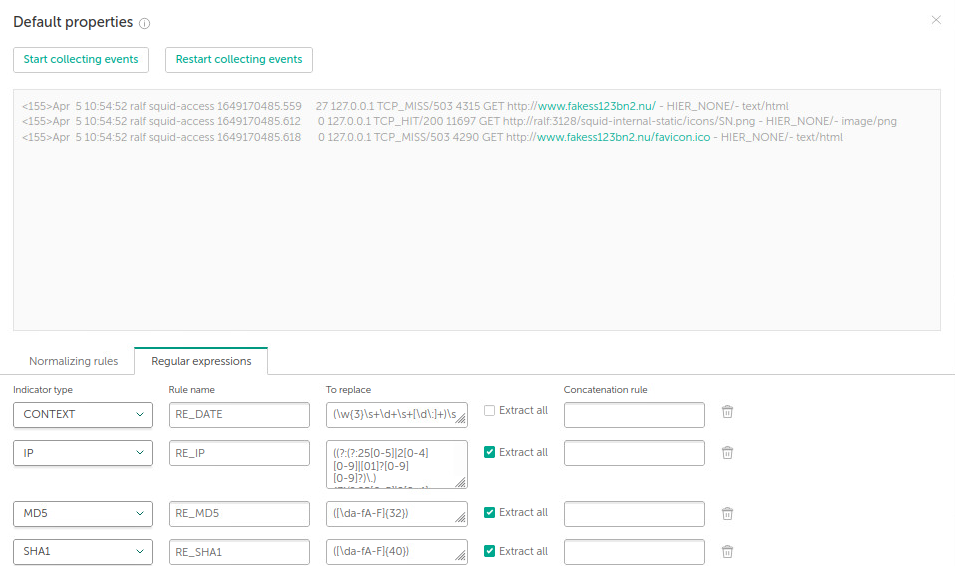
Попытаемся найти события-детекты средствами SIEM или TI-платформы, чтобы убедиться в том, что пока никаких детектов для этой угрозы (вымышленный вредоносный адрес fakess123bn2.nu) нет.
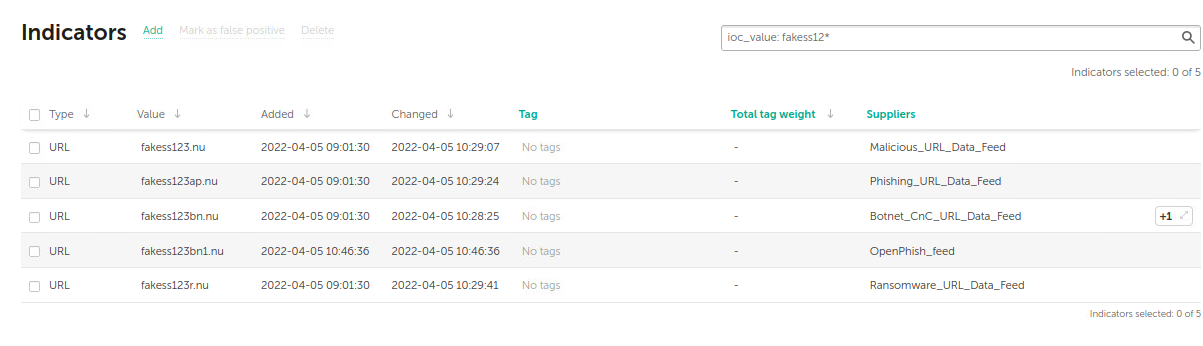
Почему пока нет и какова вероятность того, что адрес будет обнаружен в будущем? Не буду говорить за всех поставщиков индикаторов компрометации, но в продуктовом TI-портфеле «Лаборатории Касперского» есть фиды, которые дают большое покрытие на сетевом трафике и формируются на основе анонимизированной статистики и телеметрии из Kaspersky Security Network (KSN) – облачного сервиса, с которым взаимодействуют многие инсталляции продуктов «Лаборатории Касперского». KSN обрабатывает большие объёмы данных, результатом анализа которых и являются фиды TI. Если адрес станет новой популярной угрозой, он обязательно попадёт в список индикаторов с контекстом.
Другая часть потоков данных «Лаборатории Касперского» содержит индикаторы, свойственные запланированным и подготовленным заранее атакам. Эти индикаторы не массовые, они получены «Лабораторией Касперского» путём наблюдения за более чем сотней хакерских группировок, каждая из которых имеет свой почерк, инструментарий и ресурсы. Команда Kaspersky GReAT анализирует эксплойты и тактики АРТ-групп в течение 10 лет.
Портфель TI-фидов ЛК содержит как массовые, так и редкие, таргетированные индикаторы. Чем-то этот подход напоминает доспехи и щит: «доспехи» – это фиды TI, защищающие от массовых угроз, с которыми вы, наиболее вероятно, столкнётесь, а «щит» – фиды АРТ, защищающие от направленных на вас угроз. Фидами («доспехами») можно пользоваться и отдельно, но, чтобы в «доспехах» было удобнее двигаться, они интегрированы с «экзоскелетом» TI-платформы Kaspersky CyberTrace, в основе которой лежит высокопроизводительный сервис выявления индикаторов в логах.
Дополняет же образ рыцаря «меч» – сервис поиска Threat Lookup, который предлагается использовать, когда вы знаете, что искать, а не защищаетесь от вероятных или целевых угроз. Threat Lookup даёт полный набор информации о любых индикаторах, известных «Лаборатории Касперского».
Итак, допустим, имеется активное заражение, и вредоносный процесс, закрепившись на одном из узлов, обращается к центру управления, сетевой адрес которого не входит в известные списки индикаторов компрометации. Информация о попытках обращения к данному сетевому адресу центра управления сохраняется в TI-платформе. Через некоторое время SOC всё же получает ссылку в составе какого-то фида.
Например, она стала известной от регулятора, коллег, другого офиса или «Лаборатории Касперского». При этом индикатор компрометации (IoC), полученный от поставщика, может быть значительно шире одной, возможно уникальной, ссылки, он может обнаруживать все сетевые адреса, сформированные по общим правилам (так называемую «маску»).
В самом простом случае фида, полученного из открытых источников (OSINT), это может быть плоский список точных индикаторов без контекстной информации:
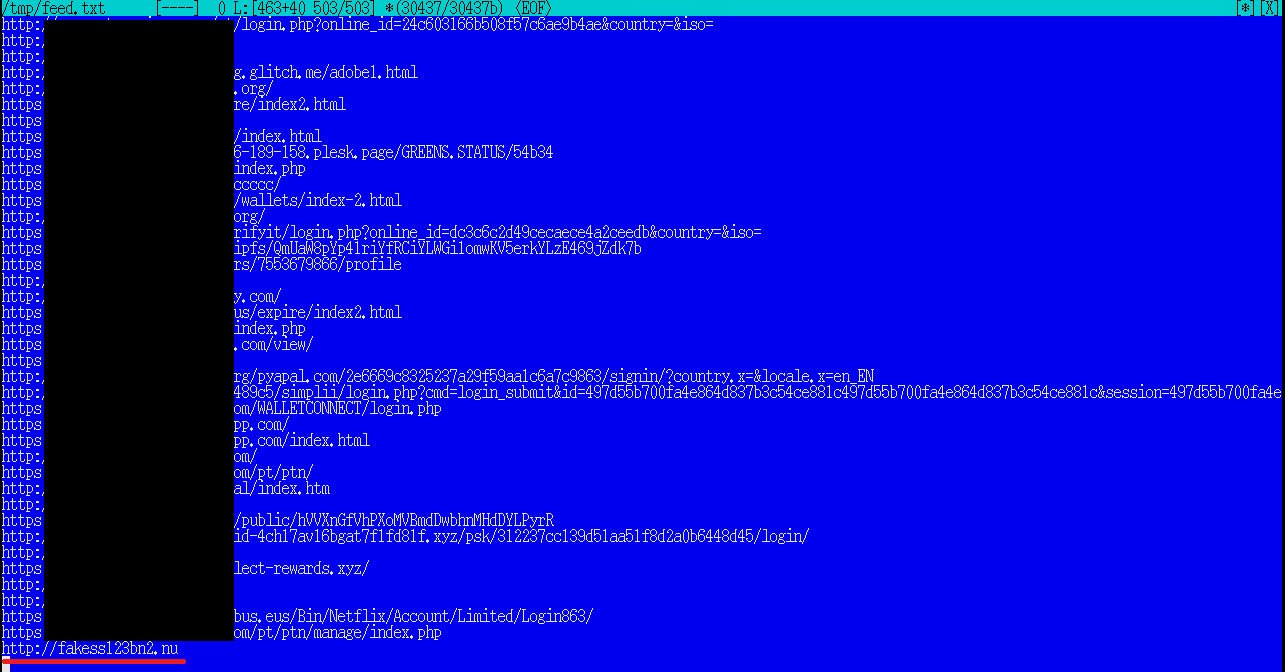
Но даже такой список без деталей можно применять в функции ретроспективного анализа TI-платформ для поиска активного заражения. Эксперты SOC постоянно задаются вопросом «Не был ли я уже взломан?». Хорошей практикой является периодический запуск задачи ретроспективного анализа (ретроскана) на глубину истории до трёх месяцев, если мы можем позволить себе хранить столько индикаторов, извлечённых из входящих событий.
Задача запускается автоматически по расписанию или аналитиком вручную, и есть детект!
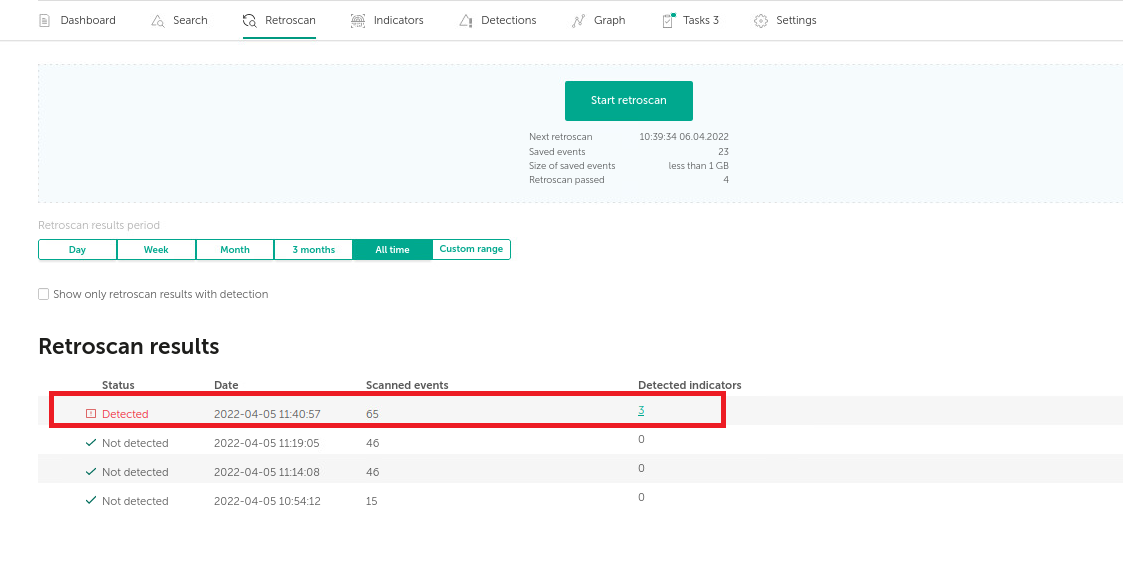
Что нам известно об индикаторе на данный момент? Обратимся к вкладке Indicators
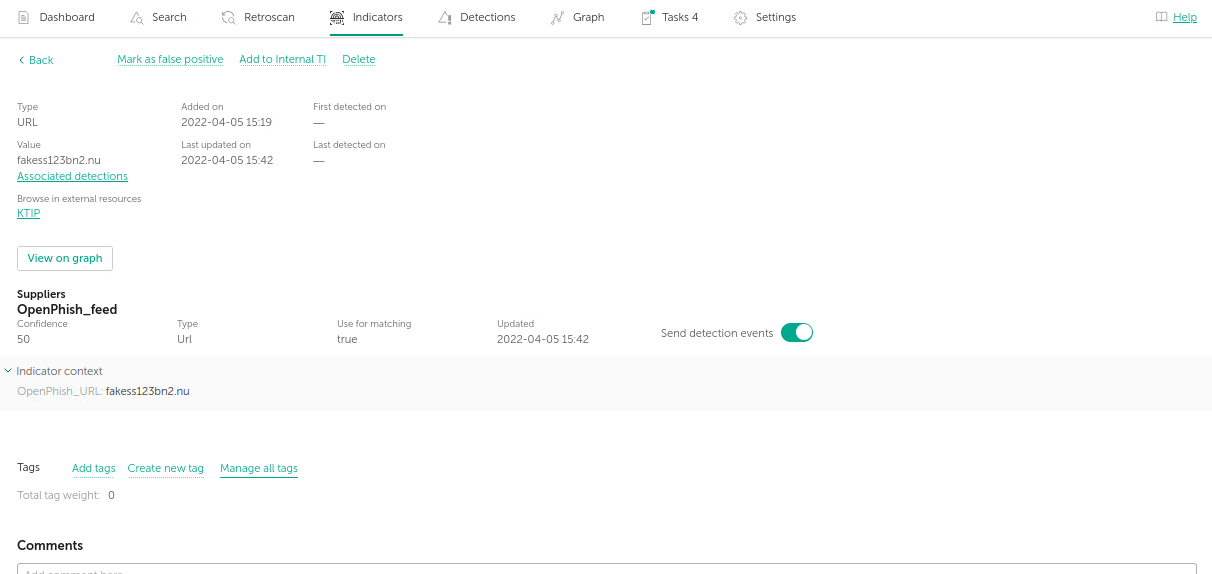
Мы уже видели, что в данном OSINT-фиде контекста нет, только список индикаторов. В случае промышленных коммерческих фидов в свойствах индикатора будут присутствовать тип ссылки (ботнет, АРТ, фишинг, криптовымогатель и т.д.), признаки времени (давний ли это индикатор), популярности, географии жертв и т.д.
Благодаря инструменту ретроскана мы узнали, что в течение недавнего периода времени были события по недавно полученным индикаторам. Вероятно, в сети есть активная угроза, которая оставалась незамеченной ранее. Естественны вопросы SOC-аналитика: какие компьютеры и пользователи были затронуты? Насколько опасна данная угроза?
Для ответов на возникающие вопросы аналитик запускает процесс реагирования на инцидент; этой области посвящено значительное количество материалов. В рамках данной статьи обозначим возможные направления действий и исследований аналитика SOC.
Плодотворным инструментом разбора инцидентов является граф, позволяющий – вручную или автоматически – добавлять на «холст» сущности, такие как индикаторы, узлы, имена пользователей, обнаруживать связи между ними. Рассматривая выявленные ретросканом детектирующие события на графе, мы видим, с какого компьютера, какой пользователь и когда посещал данный адрес.
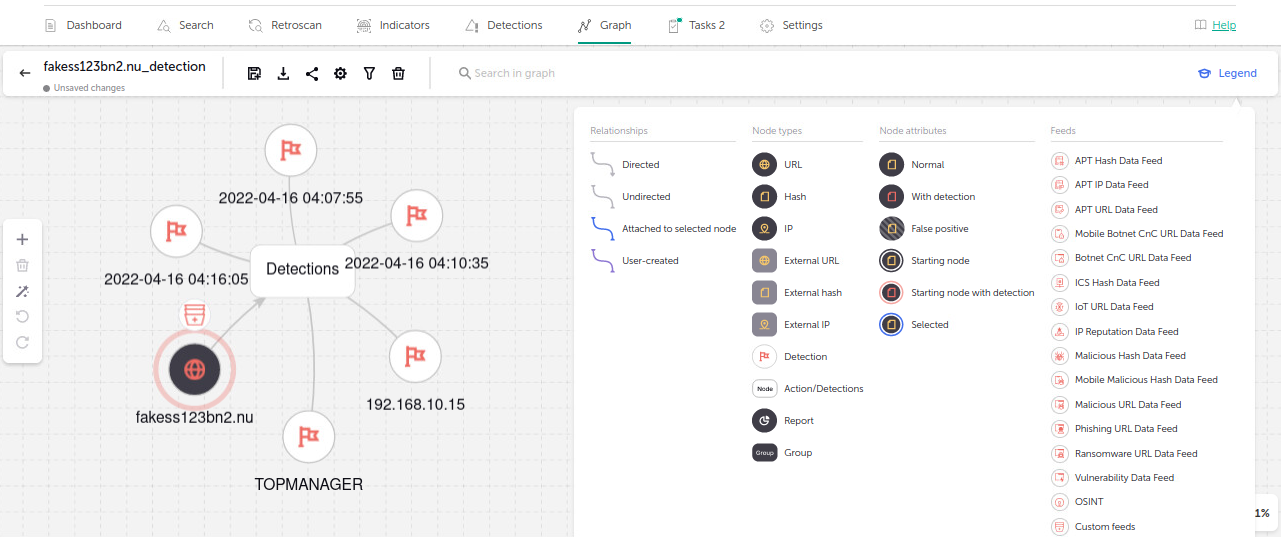
Видны также другие компьютеры, вовлечённые в исследуемую атаку. Следующая цель аналитика – понять, какие действия предпринять для устранения данной угрозы. Для этого нужно больше контекста. Например, будет полезной информация о том, какие (вредоносные) файлы в принципе часто обращаются на данный адрес, какими уязвимостями они пользуются, какие новые объекты скачиваются с данного адреса.
Мы рассмотрели, как с помощью функции ретросканирования в платформе Threat Intelligence обнаружить активную угрозу, для которой на момент заражения не было сигнатур, и соответствующий опасный адрес в интернете стал известен лишь позднее. Это помогло перейти от индикатора атаки к индикаторам компрометации.
Ретросканирование может использоваться для:
- выявления скрытых угроз, как мы показали на примере;
- прояснения способов проникновения (аналитик увидит ретродетекты по выбранным узлам);
- обнаружения уязвимостей при сканировании списка установленного программного обеспечения по базе данных уязвимостей.
Возвращаясь к нашей истории, теперь мы знаем, что искать, и можем использовать более точные инструменты – переходить от «доспехов» к «мечу». По любому индикатору мы можем опрашивать сервис Threat Lookup, получая полную информацию, известную «Лаборатории Касперского» о данном, например, URL. И если выяснится, что новые индикаторы связаны с АРТ-кампанией, мы сможем выгрузить готовые YARA-правила и использовать их для поиска и нейтрализации релевантных угрозе объектов, а также изучить АРТ-отчёт, где описываются детали и даются рекомендации по лечению.
Ключевые слова: АРТ-кампания, АРТ-отчёт, YARA-правила, ретросканирование, Threat Intelligence, TI-платформа, SIEM, события-детекты
[1] Данный интернет-адрес, как и все индикаторы в этой статье, является вымышленным и приведён исключительно для целей иллюстрации методологического подхода к мониторингу угроз.
Подпишитесь на журнал
Купите в Интернет-магазине
Facebook
Мой мир
Вконтакте
Одноклассники
Google+
|














